
图片系AI生成
3月16日,文心大模型两周年之际,百度如约发布了国内首个原生多模态大模型文心4.5,以及深度思考模型X1。与以往不同,百度本次没有选择召开发布会,而是直接宣布模型在文心一言官网上线,免费向用户开放,文心大模型4.5也面向企业用户和开发者开放,在百度智能云千帆大模型平台即可调用API。据悉,文心大模型4.5、X1也将陆续上线百度搜索、文小言APP等产品。
价格方面,文心大模型4.5的API调用输入价格为0.004元/千tokens,输出0.016元/千tokens,约为GPT4.5价格的1%;文心大模型X1定价为输入0.002元/千tokens,输出0.008元/千tokens,即将在千帆平台上线。
尽管4.5文心大模型是一个中间版本,是基于4.0版本的强化,但是通常而言,官方会出面做发布并解读产品、技术亮点,OpenAI在日前也举办了GPT4.5的线上发布会,本次百度的策略更显特殊。
行业气氛有些微妙,百度可能比以往任何时刻都需要再度证明自己。
百度纠偏,想要继续站在舞台中央
如果说DeepSeek的到来,给全球所有大模型公司都提了个醒,那么百度则通过一系列的动作,展示了应该如何留在大模型的牌桌上。
原来的百度是有些“偶像包袱”的。自OpenAI发布ChatGPT以来,百度是更早推出同类大模型产品的国内厂商,All in AI的战略也被视为具备前瞻性,凭借超前的眼光、技术储备等资源,百度被视作“中国OpenAI”。
科技行业不缺少新叙事,其魅力就在于不可预知性,大模型行业领先优势可能只能维持半年,当巨头们纷纷下重注投入生成式AI,行业又达成一个新观点,“大模型是巨头企业的游戏”,可随后DeepSeek开源、低成本的大模型引起了新的风潮,包括OpenAI、百度等在内的全球所有AI企业发现,大模型的未来言之尚早。
就像百度创始人李彦宏此前所说,“创新不能被计划,你不知道创新何时到来,你所能做的就是营造一个有利于创新的环境。”百度此前的成功在于建立了一个适合创新的环境,但是如今的百度需要甩掉“偶像包袱”,用实际行动证明自己还有留在牌桌的筹码。
好的一面是,李彦宏不惜推翻自己此前的判断,快速又坚决地推动了一系列动作,文心一言完全免费、文心4.5将在6月30日正式开源,百度核心业务搜索接入DeepSeek等。
据悉,在本次文心4.5和X1大模型发布之后,百度后续还会有文心4.5系列模型,以及下半年更先进的下一代模型5.0版本。
即便与两年前的自己对比,百度都有了明显提速,有百度内部人士表示,无论是文心4.5全面免费,还是PC和移动双端直接上现货,百度管理层几乎实在半天之内就做出决策。
但这也不意味着百度完全失去了自己的节奏,文心4.5主打的原生多模态,X1主打的多功能调用,研发储备都需要数月甚至一年,证明百度只是加快了自己的节奏,而不是失去了对技术的嗅觉。
长远来看,百度可能有一些预判失误,比如跟随OpenAI的过早商业化决策失误,但这不影响一些大模型产业的基本逻辑,更前沿的大模型仍在路上,生态的重要性继续提高。
人工智能时代的技术栈,芯片层、框架层、模型层和应用层协同优化,才能大幅提升效率,百度从昆仑芯到飞桨深度学习框架,再到文心预训练大模型,各个层面都有布局,从而降低成本,提高创新效率。
回到本次发布,为何百度选择“一言不发”,而是产品全量上线?上述百度内部人士表示,“发言不如发产品,现在百度说什么外界可能都觉得不对,最简单粗暴的方法就是用产品说话,4.5是升级,但比5.0重要性差很多,大家更有危机感了,战略调整、技术迭代的效果需要一段时间显现。”
作为百度重新证明自己的阶段产品,原生多模态大模型文心4.5,以及深度思考模型X1,透露出百度哪些动向?
文心4.5更聪明了,原生多模态才是重点
文心大模型4.5有两个关键词,国内首个万亿级参数的原生多模态大模型,Scaling Law告诉我们,参数越大模型智能越强,但是参数量到了一定级别,模型智能的提升收益大幅下降。
文心4.5的策略是通过多个模态联合建模实现协同优化,具备更精进的语言能力,理解、生成、逻辑、记忆能力全面提升,并且去幻觉、逻辑推理、代码能力显著提升。
文心大模型4.5的多项基准测试成绩优于GPT4.5、DeepSeek-V3等,并在平均分上以79.6分高于GPT4.5的79.14。
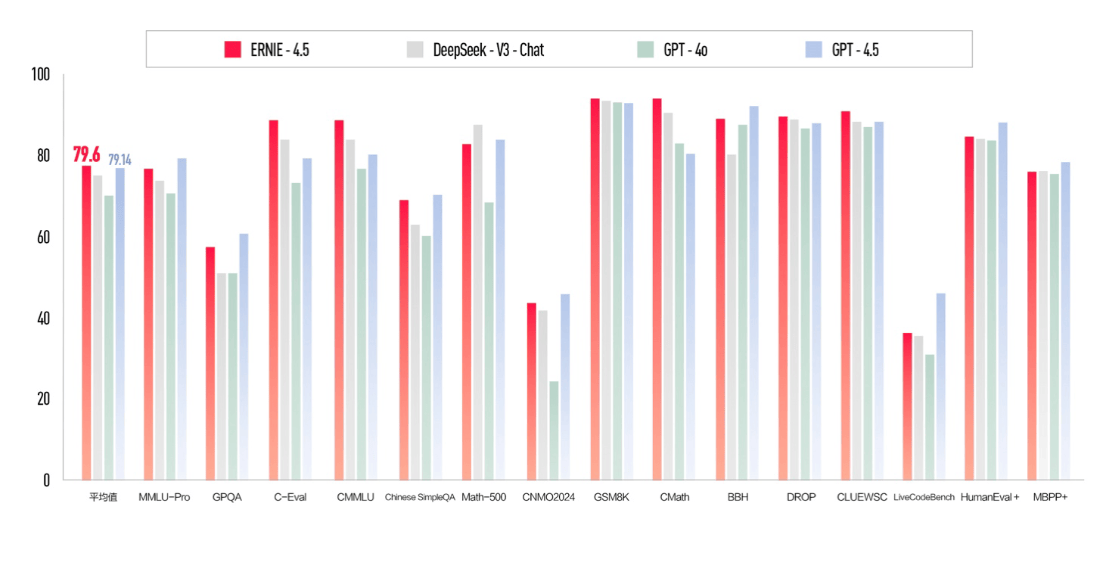
其中需要格外强调的是“原生多模态”,李彦宏此前在人民网上发文有所预告,原生多模态大模型,打破之前先训练单模态模型再拼接的方式,通过统一架构实现文本、图像、音频、视频等多模态数据的原生级融合,实现对复杂世界的统一理解,这是迈向通用人工智能(AGI)的重要一步。
简单来说,原生多模态大语言模型是从训练阶段开始,模型就利用大量不同模态的数据进行预训练,不仅可以在输入和输出端实现多模态,而且还具备强大的多模态推理能力以及跨模态迁移能力。
微软早些时间提到,基于多模态数据原生训练的每一种单模态能力,都应该超越只在单模态数据上训练的模型的性能。更重要的是,在不同模态数据学习的过程中,模型应该能够涌现出新的能力。
从行业维度看,GPT-4尚不是原生多模态大模型,它的多模态能力是模型转化实现,比如通过语音识别模型将语音转换为文字,或者通过图像识别模型提取图像内容,然后利用GPT-4的大型语言模型生成回答。回答完毕后,系统决定是向用户返回一张图片、一段文字,还是通过语音合成技术返回一段语音输出,直到GPT-4o,OpenAI显现出原生多模态的能力。
谷歌在模型能力整理滞后GPT的情况下,押注原生多模态更早,在预训练阶段的多模态数据统一输入,将文本/语音/图像/视频的数据统一输入到一个预训练模型,然后利用额外的多模态数据对其进行微调以进一步提高其有效性。
百度文心4.5也实现了一系列创新,例如多模态异构专家扩展技术,能根据模态特点构建模态异构专家,结合自适应模态感知损失函数,解决不同模态梯度不均衡问题,提升多模态融合能力。
其他如FlashMask 动态注意力掩码技术,有效提升长序列建模能力和训练效率,优化长文处理能力和多轮交互表现;时空维度表征压缩技术,大幅提升多模态数据训练效率,增强了从长视频中吸取世界知识的能力;基于知识点的大规模数据构建技术,可构建高知识密度预训练数据,提升模型学习效率,大幅降低模型幻觉;以及基于自反馈的Post-training技术,提升强化学习稳定性和鲁棒性,大幅提升预训练模型对齐人类意图能力。
文心4.5的能力也可以从图片和视频理解,、图片生成、RAG测试、逻辑测试、文本创作等方面体现。文心4.5支持上传文档、图片、音频和视频文件,兼容常见的格式,目前在文件大小上有所限制,例如单个视频文件大小不超过20M,可能与效率和成本有关。

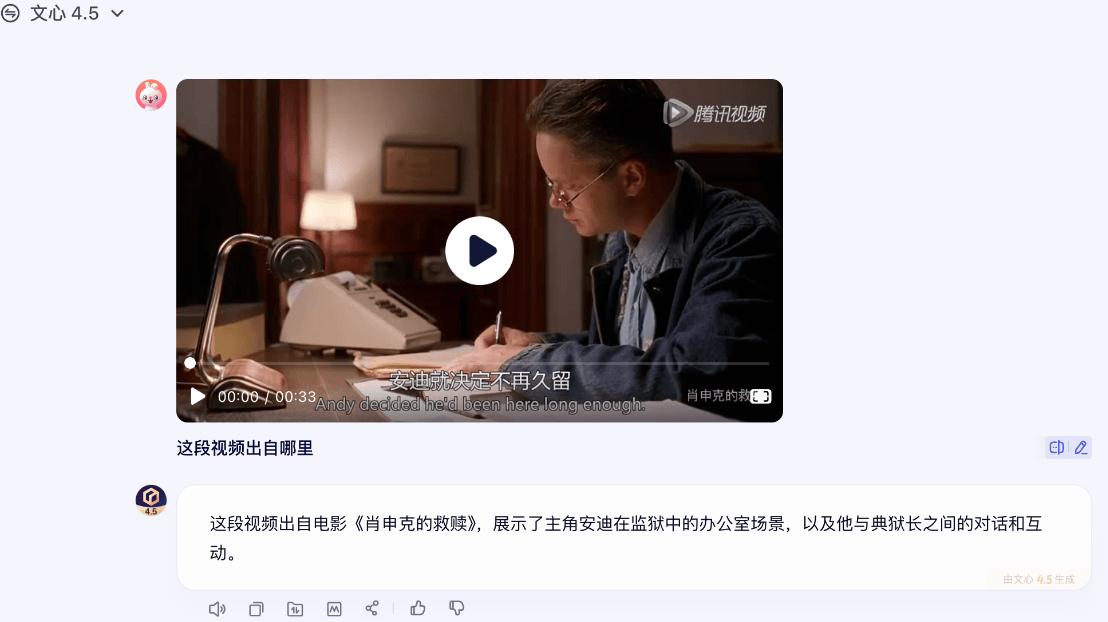
钛媒体App实测了一些应用场景,上传视频并要求文心4.5介绍视频内容,以及要求文心4.5给出视频的文字版,都能够给出准确回答。以及上传电影《肖申克的救赎》片段,温馨4.5亦能识别电影片段,并给出可能的电影情节。当然了,如果文心4.5给出合适的配乐,它也能根据视频的调性给出建议,说明了其跨模态的输出能力。

深度思考X1,AI Agent的雏形
文心X1由百度2023年10月发布的慢思考技术发展而来,具备更强的理解、规划、反思、进化能力,并同样支持多模态。
以电车难题为例,深度思考的文心X1给出了一个详细的回答,最终选择了拉下操纵杆,将列车切换到另一条轨道,它的结论是:在封闭条件下,基于功利主义最大化生存数量的原则,选择牺牲1人拯救5人。但需警惕此类逻辑被滥用,并持续反思其伦理边界。

文心X1 是能力更全面的深度思考模型,在观点输出上更为直接,“端水”现象有所减少,针对复杂问题,能够结合联网搜索最新信息,详细拆解给出全面的回复,譬如规划旅游项目,可行性更高且更符合要求。
钛媒体APP了解到,其采用了递进式强化学习训练方法,且基于思维链和行动链端到端训练,同时建立了统一的评估系统,融合多种类型的奖励机制,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现不错。
其中,多工具调用能力值得关注,也是文心X1的特色之一。目前,X1已支持高级搜索、文档问答、图片理解、AI绘图、代码解释器、网页链接读取、TreeMind树图、百度学术检索、商业信息查询、加盟信息查询、词云生成等多款工具,对于大模型应用落地是一个利好。
X1也证明了一件事,大模型本身能力的进化,实际上会淘汰掉一部分Agent,如果Agent能够被大模型原生替代,那就说明这部分Agent的价值太浅,在此领域创业注定失败。
前不久爆火并陷入争议的Manus等产品,在未来一段时间就将面临类似的烦恼,Manus的成功并并非大模型原创性突破,而是对现有技术的工程化整合,如Claude模型、Computer Use、MCP协议等,其核心创新在于将虚拟机环境与多智能体协同架构结合,使Agent能够像人类一样操作计算机完成复杂任务。
这也透露出百度另一个方向,笃定AI Agent。李彦宏也提到,推理大模型涌现出让人惊叹的深度思考能力,它将推动人工智能的一个重要应用方向,即“AI智能体”的落地,2025年可能会成为AI智能体爆发的元年。

